
Hi everyone (if someone’s there). Extracting text from images has never been easier, thanks to advanced AI models like Llama 3.2 Vision. In this guide, we’ll walk through building a simple yet powerful OCR (Optical Character Recognition) tool using Python, Streamlit, and Ollama’s AI models.
Why Use Llama 3.2 Vision for OCR?
Unlike traditional OCR methods, which rely on predefined character recognition techniques, Llama 3.2 Vision leverages AI to not only extract text but also present it in a structured and readable format. This means better accuracy, automatic formatting, and ease of use.
Understanding the Code
This application is built using Streamlit, making it interactive and user-friendly and easy to run locally. Let’s break down how it works:
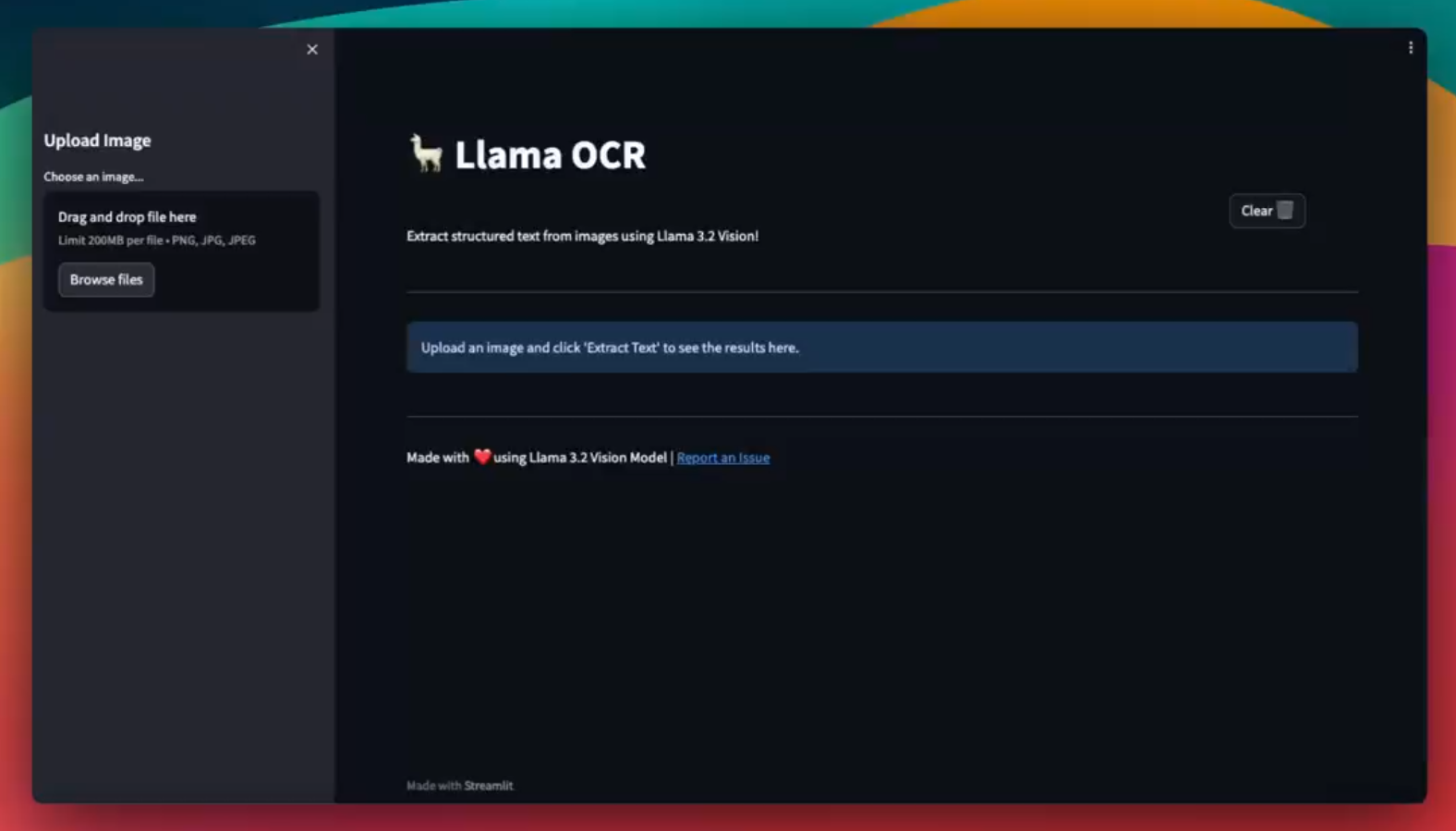
Configuring the Streamlit Page
We start by defining the page title, icon, and layout:
st.set_page_config(
page_title="Llama OCR",
page_icon="🦙",
layout="wide",
initial_sidebar_state="expanded"
)
This ensures a wide layout with an expanded sidebar, making navigation smooth.
Uploading an Image
Users can upload images through the sidebar. We’ll use st.file_uploader() to allow image selection.
uploaded_file = st.file_uploader("Choose an image...", type=['png', 'jpg', 'jpeg'])
Once an image is uploaded, it’s displayed in the sidebar using:
image = Image.open(uploaded_file)
st.image(image, caption="Uploaded Image")
Extracting Text from the Image
When the user clicks the Extract Text button, the image is sent to the Llama 3.2 Vision model for processing:
response = ollama.chat(
model='llama3.2-vision',
messages=[{
'role': 'user',
'content': """Analyze the text in the provided image. Extract all readable content
and present it in a structured Markdown format.""",
'images': [uploaded_file.getvalue()]
}]
)
The extracted text is stored in st.session_state so it persists across interactions.
Displaying the Extracted Text
Once the processing is complete, the extracted text is displayed in the main content area using:
st.markdown(st.session_state['ocr_result'])
If no text has been extracted yet, an informational message guides the user.
Running the Application locally
Run these following commands in your terminal:
- Clone the repository:
git clone https://github.com/piktx/local-ocr.git
cd local-ocr
- Install dependencies:
pip install -r requirements.txt
- Start Ollama service:
ollama serve
- Launch the Streamlit app:
streamlit run app.py
This will start a local server, and the tool will be accessible via the displayed URL (usually http://localhost:8501).
Final Thoughts
With just a few lines of code, you can built an AI-powered OCR tool that can extract structured text from images with impressive accuracy and the best part is, you can do all this on your local machine. Whether you need to digitize documents, extract notes, or process scanned images, Llama 3.2 Vision provides a seamless solution.
Last but not the least, If you liked this project, don’t forget to give it a star on Github